About Me
I have been programming ever since I realized programming was a thing you could do. By the time I got into university, computer science was my passion; to the point that I considered working on my university computer science assignments to be my relaxation time. I graduated from the University of Waterloo with a Bachelor's degree in Computer Science, and a minor in Combinatorics and Optimization. Now I solve problems, mostly using programming, preferably involving optimization.
From watching computer science conference presentations in my free time to timing parts of my daily routine to see where I can save time; I'm always looking to challenge and improve myself both in computer science and my overall life. Several of these projects are a direct result of this. I wanted to improve my knowledge of low-level programming, so I designed a computer. I had an assignment to make a game, so I made a game engine and two games on top of it. I had to create a raytracer, so I challenged myself to make it fast enough to run in real-time.
My major hobbies include programming, learning about programming, self improvement, and reading.
Optimization Reports
A report on how to load and represent XML using less peak memory than the size of the file with minimal overhead.
Alternatively, an example of how to reduce memory usage by a factor of 10:
Design Decisions for Efficient Extensible Markup Language Parsing
A report on how to take a data processing tool from "leave running overnight and it might run out of memory on the 64gb servers" to "your laptop will be done before you get back with your coffee": Reading, Writing, and (R)Optimizations
Computering
This pageSort of a beginner's guide to thinking like a computer. Sort of a beginner's guide to Java. Sort of a beginner's guide to profiting with infinite friends.

Real-time Raytracer
In the winter of 2018, I took the Introduction to Computer Graphics course at the University of Waterloo (CS 488). Among other things this course requires students to create their own raytracer given only the code to build a scene in Lua. Apart from standard raytracer features, I optimized the performance enough to enable real-time raytracing.

I focused on making my raytracer as fast as possible. The final result was that it was able to render a 200x200 scene with basic geometry and less basic cow meshes at 30 FPS while allowing a user to move the camera around the scene.
The raytracer was built on top of multi-threaded task tree execution system I designed. It allowed for each task to create child tasks which must be finished before it is considered done, and queue up tasks to be run after the task is finished. For the raytracer, this was used for tasks like collecting the colour information from reflected rays in child tasks before a final task combines their information into a final colour.
The raytracer implemented reflections and refractions, with varying amounts of glossiness, as in this scene:

I also implemented computational solid geometry to allow for the addition and subtraction of geometry to form more complex shapes, as in this scene which combines several cows together and then subtracts a sphere from them:

Instead of just changing surface properties like diffuse colour using textures or Perlin noise, I decided to allow any surface property to be controlled. As an example, this scene shows a sphere with different Perlin noise functions controlling each of the RGB channels, reflectivity and glossiness:
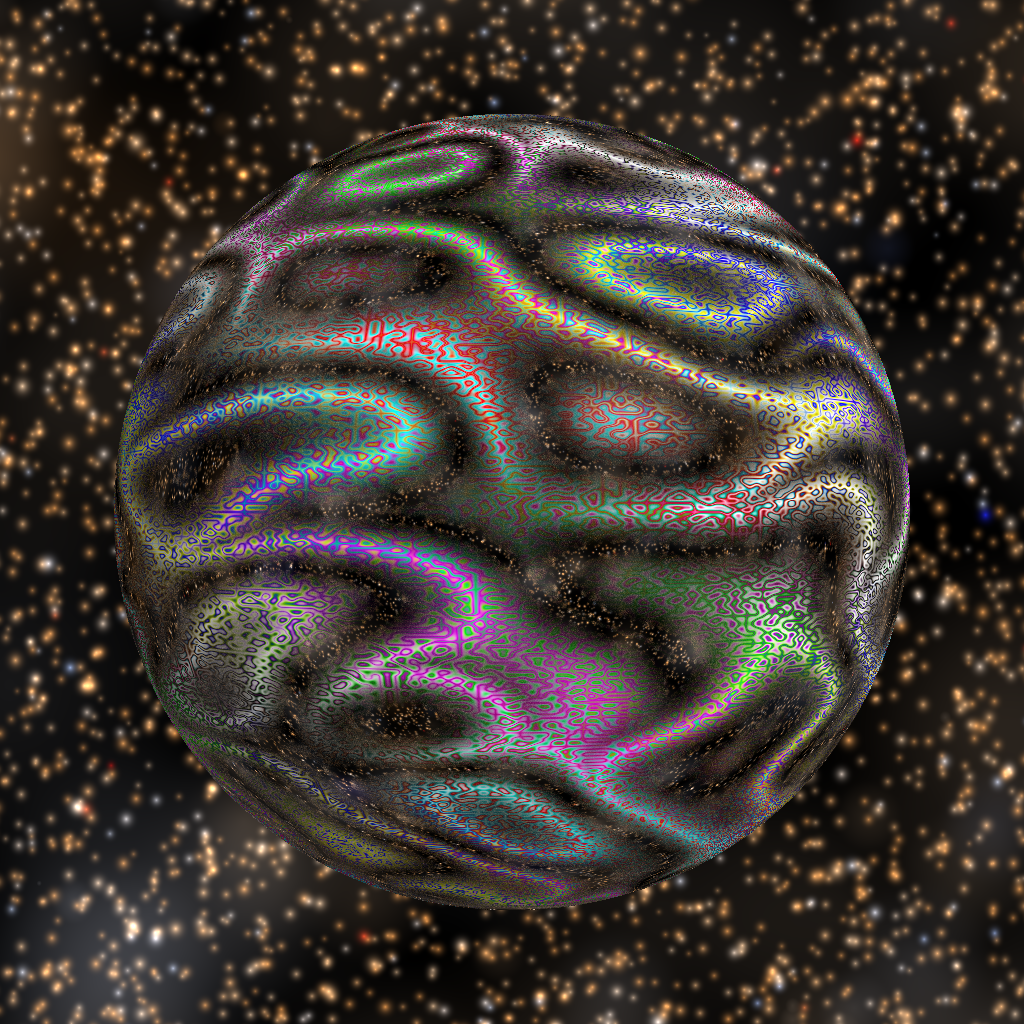
In order to provide a more interesting background for the raytracer, I designed a system to randomly generate stars of various sizes with random colours (biased towards a realistic distribution and then tweaked for looks). The stars were designed to have a sharply defined core and a softer outer glow. The system also generates a handful of large clouds meant to simulate galaxies. The scene below shows only a reflective sphere to show off the entirety of the starfield:

As an overall demonstration scene, this 2048x2048 scene shows off most features, and has over 4 million triangles in its various meshes, largely due to including the trees and grass as meshes; despite this it rendered in under 2 hours on a laptop:


ARM Microkernel
In the summer of 2017, I took the real-time programming course at the University of Waterloo (CS 452 / Trains). This course requires students to design their own microkernel and then use it to control a model train set.
I did the kernel design part of the course independently and the train control part with a partner; as the first part presented interesting design choices we wanted to experiment with. The controller was an ARM920T from the year 2000.
The only code provided for the course was an intentionally flawed code snippet for basic communication over the serial ports. All other functionality had to be programmed in either C or assembly without external libraries.
The microkernel was designed to concurrently run tasks, providing mainly the core functionality of task creation and communication. All other functionality, such as a name server for determining which currently running task is which, or a time server, was implemented as distinct tasks outside the kernel.
Since high performance inter-task communication and context switching allows for much more flexible and modular designs, I made sure to make my communication code as efficient as possible. The main performance metric was sending 4 bytes, and getting a reply from the target task.
Optimization on the level of examining each assembly instruction in hot code paths led to each send, receive, and reply operation taking 2.7 microseconds, and each context switch taking 0.6 microseconds. For context, according to this analysis the Linux kernel on the 2012 Intel Xeon E5-2620 takes about 1.3 microseconds for a context switch, which is more than double my time despite having 12 years more advanced hardware. Although in the defense of the Linux kernel developers, they have a much more advanced kernel.
The latter half of the course consisted of using a microkernel to control multiple trains in a train set and avoid collisions. The final project involved using a microkernel to control two trains connected to a complex assembly allowing them to act as a basic printer; with which we printed some text and drew a portrait of the professor.
From September 2017 to December 2017, I worked as a Software Development Engineer Intern at Adeptmind, a machine learning enhanced e-commerce search solution. I independently designed and developed a Python based distributed web crawler and a companion statistics monitoring tool using Golang.
While working at Adeptmind my main task was to develop a distributed web crawler that could efficiently scale up, and the tools to control and monitor it. I also did a small amount of experimentation in Tensorflow.
The web crawler was built in Python, and used an architecture of a master controller responsible only for sending out commands with 3 sets of slave systems which performed different tasks. The system was built alongside a sharded mongoDB cluster for storage and continuity when shutdown.
The system was designed to be easy to scale and control. Adding a new physical system is as simple as running a setup script and informing the master controller of its existence. The master controller is then able to automatically start, shutdown, and even update the slave software. This means that despite the software being run on multiple systems, updating all systems is as simple as updating the master code repository and resetting each running slave.
The distributed crawler treated crawling any specific site as a distinct web crawling task, and provided control over each task individually. A local website was created which allowed authorized users on the local network to create, stop, and modify crawling tasks without any technical expertise required.
The system allowed users complete control over the progress of a crawl. For most tasks a configurable system could be used to control behaviour such as deciding which found links to crawl in what order. For complex tasks, users are able to provide code to precisely define behaviour.
The monitoring tool was designed in Golang to take advantage of the language's channel based design. It uses a server which monitors and stores a short history for each data source of interest. Users can then view a live stream of updates for the data they are interested in, including applying various filters or functions such as seeing only the maximum value in a certain time period.
With both systems, any non-technical user is able to easily create a new distributed crawling task and have live monitoring of and control over the progress of the crawl.
From January 2017 to April 2016 I worked as a GPU C++ Development Tools Architect at NVIDIA, working on internal tools related to performance monitoring, adding new features and primarily improving their performance in terms of speed and memory usage.
While working at NVIDIA, I worked on two major projects: improvements to a data capturing tool, and performance optimization for a data processing tool.
I added a new feature to the data capturing tool to automatically align data captured for the same tests but at different times. I also improved its runtime performance during data recording and writing.
For the data processing tool, I was tasked first with preventing it from crashing on certain large inputs on which it would run out of memory and crash. After that, I was given free reign to optimize both memory usage and runtime speed, and managed to make the tool 20 times faster while using 6 times less memory. A full report of my efforts can be found here: Reading, Writing, and (R)Optimizations. Since this specific tool is an important part of the performance profiling system at NVIDIA, these optimizations save a significant amount of computing time.
For memory optimizations, the original design of the tool meant it could require contiguous chunks of free memory of unbounded size. I made the tool use 6 times less memory on average, and also limited the amount of contiguous memory it could require to an adjustable value set to 32 megabytes by default. For performance optimizations, I did various general optimizations and added multithreading, scaling to the number of cores on the system, to make the tool 20 times faster.
On one of my largest test cases (a real use case that a coworker had found), the original tool had to be left on overnight to run and would require enough memory to crash a machine with 128 gigabytes. With my improvements, the tool finished the test case in 40 minutes using only 25 gigabytes (and was significantly slowed down due to paging, since I ran it on a machine with only 16 gigabytes of ram).
From May 2016 to August 2016 I worked as a Software Developer at Big Viking Games, on the Platforms, Tools, and Research team, creating new tools and doing research for the games platform.
While working at Big Viking Games, I worked on three major projects, a file processing pipeline, a C++ library based on Cap'n Proto capable of being converted to javascript via Emscripten, and research into space efficient ways to store, copy, and modify collections of files.
The file processing pipeline was designed to replace an older version used to process all the contents (art assets, metadata, etc.) for a game, and produce the final, production ready files. Since this would often take a minute and a half, slowing down the development cycle, I was tasked with designing a faster version. The new content processing pipeline used an XML file describing the desired operations (file searches, filters, flow control, content specific processing, combining, etc.), as streams of data moving between operations. Once activated, the pipeline could concurrently execute multiple operations on multiple input files at once, with execution order being limited only by the dependencies defined in the XML per input file (i.e. the final operation in a series could be run on one file, at the same time as the first operation running on a different file, and both files would end up going through each of the operations in order).
In order to further improve efficiency, the new processing pipeline came with a system for monitoring the filesystem for changes, and rerunning the pipeline if any inputs changed. In the end, the new version was capable of running in less than a third of the time of the old version, about 22 seconds, and making much better use of multiple cores when available.
My second project was to design an example system using the serialization and remote protocol call (RPC) library Cap'n Proto in C++, capable of being transpiled to javascript using Emscripten. The main challenge being that Cap'n Proto did not at the time have a javascript implementation which supported RPC, and the C++ implementation of RPC would not work in the javascript environment when transpiled. In the end, I made use of existing abstractions in the Cap'n Proto library to replace the pieces of the RPC system which would not work in javascript.
My final project was to research and propose a system for managing the storage, copying, and modification of collections of files at a large scale. Each file collection was allowed to be anywhere from empty, to several gigabytes large, with zero to hundreds of thousands of files. The system was required to support copying entire projects, and allowing the original and copy to be independently modified, without having to store duplicates of the unchanged content. The system was required to scale well in terms of both space used, and time, under heavy load.
My research initially led me to develop a prototype in ZFS, a copy on write filesystem which allowed thousands of file collections with a total size in the terabytes, while only using a few tens of gigabytes of space. Unfortunately, further testing showed that the more collections the prototype was storing, the longer it would take to copy a collection, taking approximately (number of collections / 1000) seconds. Since the system needed to scale up to potentially multiple collections copied per second, the linear scaling cost for copying was unacceptable.
I ended up turning to the younger brother of ZFS, BTRFS, a similar filesystem to ZFS. While I had initially avoided BTRFS due to concerns about its stability (on the BTRFS FAQ, the short answer to "Is btrfs stable?", is "Maybe", FAQ), the poor scaling of ZFS forced me to give it a chance, especially since a lot of the stability concerns for BTRFS were anecdotal and starting to grow old. After updating the prototype to be able to use BTRFS, I found it offered similar space saving performance to ZFS, and scaled much better when it came to copying collections.
My final contribution to the storage system project was a Python script which could be used to automatically test the performance of any implementation under multiple conditions of file sizes, collections sizes, concurrent requests, and more. The script would track both the overall test statistics, such as apparent and actual space used, average time to copy or create collections, and more, as well as real time statistics such as CPU and RAM usage, and disk I/O. The script was also able to graph the resulting data from multiple tests, to better compare different implementations.
From September 2015 to December 2015 I worked as a Software Developer at Crank Software Inc. creating new tools and improving the memory usage of existing systems for the Storyboard Suite.
During my time at Crank Software Inc. I worked on three major projects, a 9-patch image editor and related tools, a new Lua API for accessing the user interface model, and reducing the memory usage of the file loader. Throughout this I also did minor bugfixes and improvements to the Storyboard Suite.
The 9-patch image editor I created in Java 8 automatically finds the ideal set of guidelines for scaling an image, but still allows for customization. The colours of the guidelines used are automatically set to contrast with the colours of the image for easy visibility.
One frequent request was the ability to navigate through the object model of the user interface using Lua. To that end, I created a new lightweight LUA api in ANSI C89 for navigating the model that fits into the existing APIs.
Since the Storyboard Engine is intended to be used on extremely memory constrained systems, I spent some time on reducing the memory used by the file loader in ANSI C89. The existing file loader was a fairly standard implementation which had the advantage of being incredibly fast due to doing very little.
I managed to reduce memory usage to about a tenth of the memory originally used, while even in the worst case my new version runs less than three times slower (it still runs in less than a tenth of a second on all inputs).
A detailed analysis I wrote of the different strategies used to reduce memory usage and their impact is available here: Design Decisions for Efficient Extensible Markup Language Parsing.
From January 2015 to April 2015 I worked as an Associate Programmer at Relic Entertainment working on tools and bugfixes for Company of Heroes 2 and the Essence Engine.
My time at Relic Entertainment was divided between minor tool improvements, bugfixes, optimization, and designing/developing a major new system for the Essence Engine Worldbuilder inside of an agile and version controlled work environment.
Minor tool improvements was simply taking improvements, going into a cycle of implementing and testing them, getting feedback from the original requester, and when everyone is happy, submitting the changes.
Bugfixes required reading and debugging large amounts of code, along with looking through content files for any errors.
At one point I was asked to look into optimizing the user interface, in ActionScript/Scaleform. Despite the user interface already being heavily optimized, I still managed to improve the speed on the more cpu intensive frames.
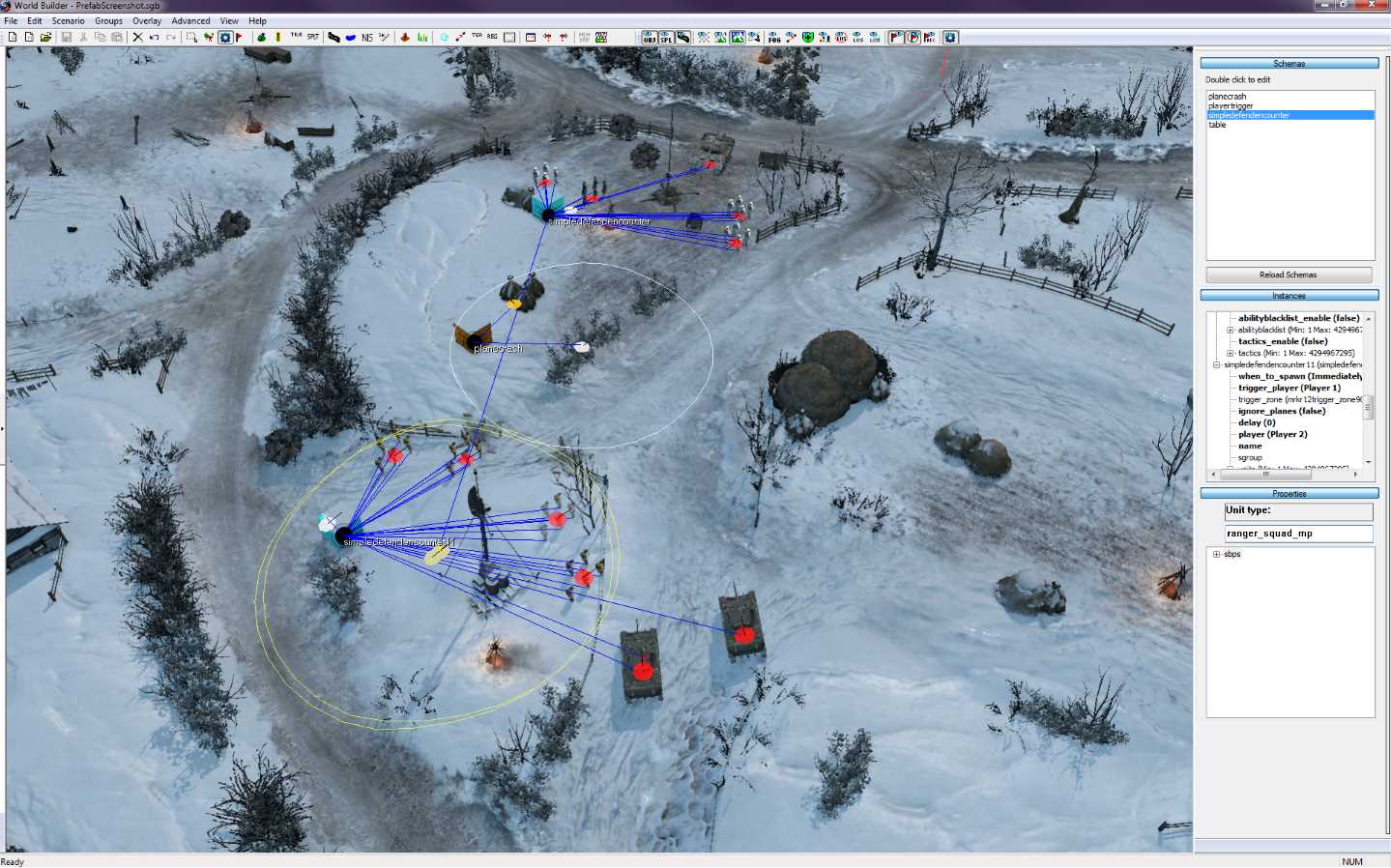
The major focus of my time at Relic Entertainment was the design and development of a new prefab system for the Worldbuilder. The aim of the system was to give mission creators the freedom to insert common scripted events such as triggered plane crashes, or skirmishes between two teams, without worrying about the complex process of placing entities, naming them, and linking them all together with complex scripts. Instead the process was simplified to placing a prefab, and changing any values that differ from the normal expected usage. This made the difference between half an hour of work followed by hours of testing and debugging, to five minutes of work.
The prefab system was designed to allow for the prefab templates to change over time, with the changes reflecting in existing usages. For instance, if an encounter was originally designed to spawn three units, and missions were created with the prefab, later changing the prefab to spawning four units would mean missions created before this change would still end up spawning four units instead of three. Changes such as these only occurred if the relevant values (in this case, the number of units to spawn), were unspecified by whoever originally placed the prefab in the mission. These kinds of changes could also be triggered inside of the worldbuilder, mostly for easily creating templates and viewing the results, and all prefabs using that template would be updated on the fly to match the changes, keeping all current specified values when possible.
A defend encounter being setup with an attacking and defending team, along with a plane crash trigger in between them:
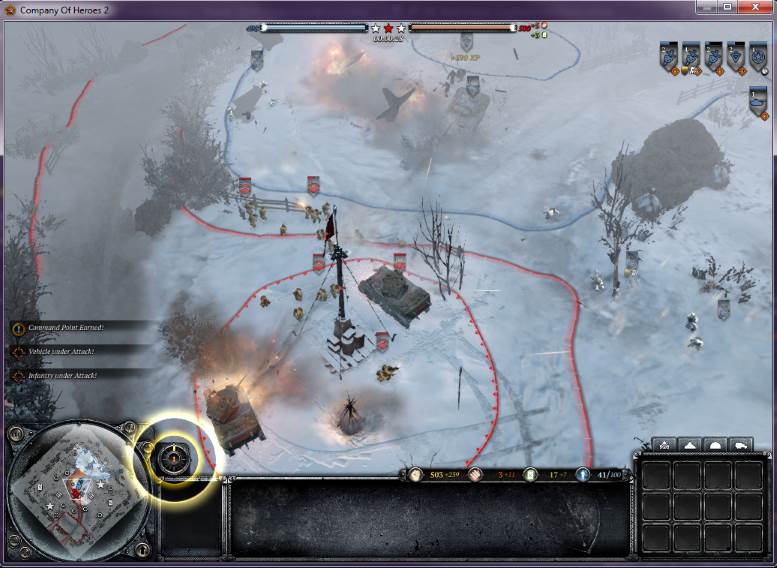
The same mission being run in game. Note the blue team moving to attack the defending red team, and the flaming result of the plane crash:
Game Engine
A 2d game engine I designed and created using python. It was written to be as unnassuming as possible, allowing developers to add anything they want without having to modify the engine, while still making it possible to produce a game with the provided resources.
The engine has the following features:
A powerful entity based design, capable of handling hundreds of entities at once. Entities and their controlling scripts are loaded at runtime allowing each entity to be created with it's own unique collection of variables and behaviours all without modifying the engine. Entities are capable of accessing all parts of the engine in order to change the world as necessary, and control other entities. An entities script can also take control of rendering the entity, or allow the engine to do the work.
Additional subsystems loaded at runtime, allowing developers to add their own major subsystems without modifying the engine. For example a system to track and update a player's score.
A custom dynamic lighting algorithm:

A complete map editor, allowing the use of any textures in the right folder at startup. Textures can be animated, and set to emit particles.
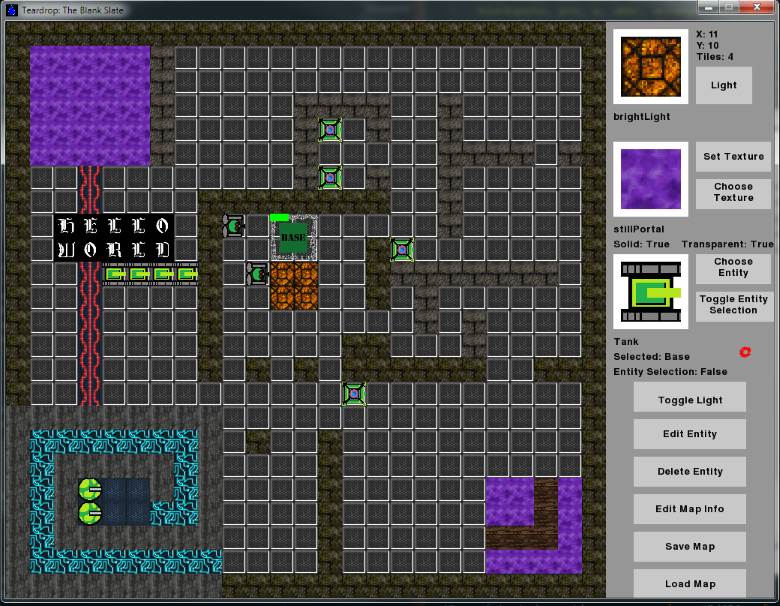
An ingame console allowing any variables to be modified. All subsystems and modules are automatically scanned to gather a directory of variables to help users find the right things to modify. Any system or entity can also specify a list of variables to be excluded from this scan. The console can be disabled, or password locked.
Computer
In my quest to further my understanding of how computers work, I designed a computer system from logic gates all the way up to a high level language.
With the help of the resources available at Nand2Tetris, I designed a computer from the logic gates up to cpu and ram. I then created a high level language, and a compiler to turn it into machine code for the computer. The end result was tested with a simple clone of space invaders.

Ash
Ash is a two player game I wrote in python as a sandbox for testing out AI strategies. Code available here: TheNotChosenOne/ash.
Ash features an open framework allowing for simple creation of new gamemodes and artificial intelligences. There are currently two AIs, one decision tree based AI, and one neural network based AI. The neural network AI can be customized by changing any of it's hundreds of weightings, and new AIs can be created simply by finding the right set of weightings. To that end there is a genetic algorithm based system which can be used to find weightings which produce competent AIs. The preview image above shows a game between a neural network created through the genetic algorithms on the left, and the decision tree based AI on the right.
Kinput
A computer science professor of mine made an offhand comment hinting that anyone who could write a program entirely using the Microsoft Kinect and interpretive dance would be rewarded. I'm not really a dancer but I still got a chocolate bar for doing this fun project.
This system was written with C# and the Kinect SDK. It can currently be set to track the users entire body, or just their hands. In the future it could be modified to accept any point or set of points to track, and therefore find use as an input system for people who, for whatever reason, cannot use a standard keyboard.

Explore
A hand painted android game, with a procedurally generated infinite world.
Explore features hand painted textures, and an infinitely large, procedurally generated world. The player is allowed to wander endlessly in any direction while the map generates on the fly using a variant of Conway's Game of Life. The system ensures both that the player cannot get stuck, and that locations important to the game plot would eventually be stumbled upon, multiple times if necessary.